Project idea: ArticleChurner
[UPDATE 2014-09-09] Apparently I put the prototype on GitHub and then forgot about that. Get it and fork it here.[/UPDATE]
Do you have a big pile of articles that you want to keep to "read later" (= throw away later)? I managed such a list (several in fact) over the years of my studies. It consisted of several stages of filtering: first the RSS reader with some arXiv categories, where I marked many as read without reading more than the title, then later on "saving" some of those where I actually read the abstract. Much later, I took some time to copy the most promising title+abstracts into a list in my PKM (personal knowledge management) wiki (could have used any text document as well). I never read anything in detail unless in came up somehow in my research, which is why I wouldn't need the list at all.
The process of making such lists is helpful nevertheless: I get the feeling that I have some idea what is going on in my field and more specifically in my areas of specialization. Even if it's only a feeling, I like it (and I guess it's not only a feeling).
But what do you do with the final list? Some people add a stage where they print out some articles which sound particularly promising, only to accumulate an actual pile on their desk. This is a "pile of shame" (a term I got from Scott Hanselman). Don't do that.
While I think one should not try to read all that (there are more important things, or you'd be already reading all that anyway), I don't like the idea of just killing the list (or the list-making process). As I said before, the process of making the list enlarges my knowledge about what's going on, and sometimes I learn useful facts. The crucial part of the list-making is effective filtering, by which I mean throwing away something as soon as you realize it's not going to be valuable enough, and doing that in stages with increasing rigour. In the end, one should come up with several stages of lists which are shorter and shorter, going down to a list with 1 or 2 articles which you then read from beginning to end. And the other articles? Well, for decision-making you need information, so you don't read just the title or the abstract (as in the first stages of filtering) but you skim through the paper, reading the table of contents, the introduction and the reference section. Very often the abstract was quite misleading and the paper is mostly about something else. I think it's worthwhile to record these small insights somewhere to not be fooled again ;-)
A problem/solution with the incremental filtering approach are incentives. I certainly don't like the idea of reading a whole math paper if it's not definitely useful for my research (it takes a lot of time)! So, I don't expect from myself to read anything from beginning to end. This makes me much more likely to start reading. To continue reading where I left off, I have to take notes. This note-taking is work, so one has to align incentives such that the work seems less intimidating.
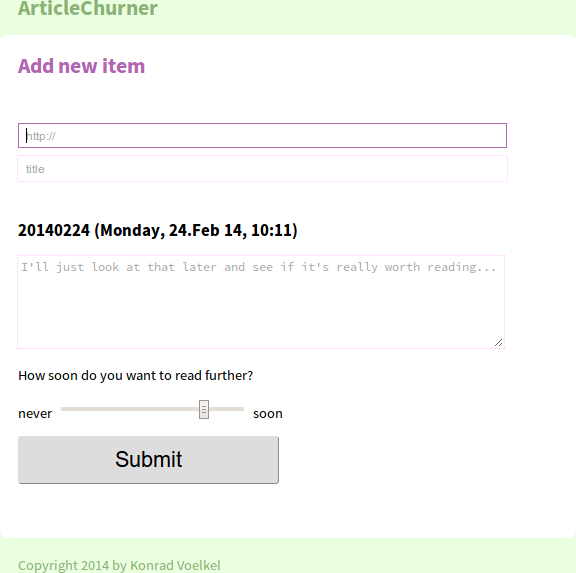
Another problem with the incremental filtering approach is that it takes so much time to even skim through an article that I cannot reasonably expect to get through a 100-item list in one day, so I have to start somewhere, pause, and continue on another day. This means picking something to start with, which is always hard if you have so many (interesting) alternatives. My solution is randomness: I wrote a small program (that I called "ArticleChurner") that picks for me. It lets me skip over to the next article only if I provide some notes on my reading and give some rating how likely I want to see it again. Rating 10 articles all have the same uniform probability to show up, while rating 1 articles are much less likely to show up. Rating 0 means it's killed from the list (but the notes are preserved). That way, I can easily add stuff to the list (with rating 10 initially) and churn through the articles. The less interesting stuff will be skimmed once and then show up less often until it finally lands in the archive.
By writing down the notes I get a sense of accomplishment that is already a huge incentive to skim through more articles and get the list smaller (is this gamification?). It also is so much work that I now kick off items from the list (move to the archive with a small comment) much more easily. If this trend continues, my list will be a lot smaller very soon - and my knowledge as well as my notes on interesting articles will be much larger. This does take some time, but it feels infinitely better to me than just throwing the list away. It feels as if I'm not missing anything (though I certainly still do, and that's a good thing, since time is very limited).
One question is: can such a system be improved, integrated with arXiv, MathSciNet, JabRef, etc.? I would love to have it integrated with my RSS reader (Feedly), as I have done with arXiv (via a userscript), but that's just my workflow. My prototype is also very cumbersome and uses Markdown because that's what I use in my PKM wiki. Other people might prefer other markup languages.
Anyway, I think some piece of software could be useful for a larger audience than just me. Maybe this exists already? In the various bibliography management tools I've evaluated (some time ago) I didn't notice this. Also, bibliography management has other, different requirements. Is it really necessary to mix the software proposed here with a full-blown library? I don't think so, as long as data can flow between tools.
Here are screenshots of the current prototype:


[UPDATE 2015-03-12]
I'm still using ArticleChurner as my only large-scale reference management system (for concrete projects I have small bibtex files that I edit with JabRef). It's useful since I know how to circumvent the bugs (which also prevents me from fixing them).
The associated javascript userscripts for easy import from ArXiV and MathSciNet that I use all the time have seen some minor improvements. My brother tells me one should do this with JQuery (which I don't know yet), so this might be a good opportunity for me to learn it. If I ever find time again (unlikely!).
There is still hope that someone comes along and finds the idea behind ArticleChurner sufficiently nice to urge me into fixing the (known) bugs, but that hasn't happened yet. Why won't you be that person? After all, you read further than I ever imagined anyone to do ...
See also my other project ideas.
